
迁移乌云镜像
wooyun镜像迁移到opensearch
mariadb 10.3.10
处理掉详情中的html标签
1 | -- 漏洞详情处理 |
处理完如下

自己PC没有公网ip,用frp开了一个。

速度可观

数据转到了阿里云odps

到开放搜索里新建应用

后面按操作来就ok了
自有源
这里没有记录,大致思想就是把图片传到微博图床上,同步生成对应json,页面加载时通过读取json来加载对应图片,其次也要对bug数据进行清理,再打包成json,同样在加载时进行读取。整体文件不大,然后全都放到腾讯云COS上,加个CDN,配置一下其他的优化。
发现了一些问题就是,图片丢失严重,如下是丢失数量
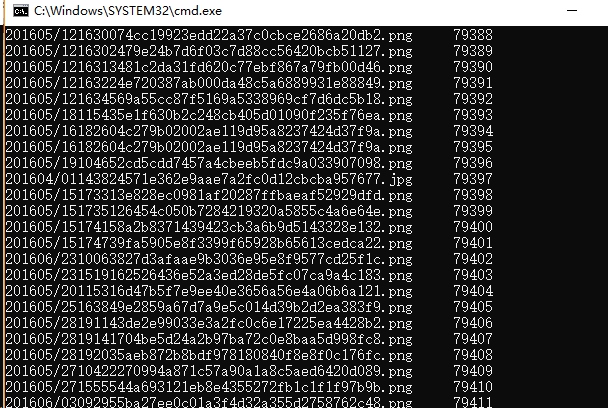
一共丢了近8w张图,而正常的数量大概是29w,平均下来大概五张图里有一张是没办法加载的。
然后我发现,似乎这里https://bugs.shuimugan.com给出来的是正常的。
然后进一步研究发现,其实也不是这样的,它也有许多图片丢失,不过的确比我这里多了一些图,写个脚本跑一跑,把能跑下来的跑下来先。

然后这边一边下载一边上传,初步拿到了6770张图片。
再进一步研究发现,它有些图片在upload下,有的在wooyun/upload下。
1 | https://images-bugs.shuimugan.com/upload/201409/101512561d3523ba6b1c737600a0af1eed4e94e4.png.webp |
觉得php还是有点无力,把丢失的图片写入到down.txt,用bash写一个下载。
1 | cat down.txt | awk '{match($0, /([[:alnum:]]+)\/([[:print:]]+)/, info);system("wget https://images-bugs.shuimugan.com/wooyun/upload/"info[0]".webp -P images/"info[1])}' |
查下载的数量
1 | ls -R|grep \.webp$|wc -l |
去重复之后,一共找到了69433张图

批量重命名,主要是因为.webp拓展名和其他部分的代码有冲突
1 | for f in */*;do mv "$f" `echo "$f" | sed 's/.webp$//g' `; done |
看看进度
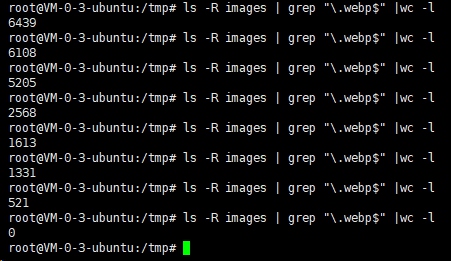
然后上传微博图床
感觉还要上传很久
部分细节
关于tag
文章是导出成json的,tag部分没有做好,数据库给出的tag内容类似这样
1 | %E8%AE%BE%E8%AE%A1%E7%BC%BA%E9%99%B7%2F%E8%BE%B9%E7%95%8C%E7%BB%95%E8%BF%87>设计缺陷/边界绕过%E9%80%BB%E8%BE%91%E9%94%99%E8%AF%AF>逻辑错误 |
我之前把它decode然后取>进行分割,觉得好像标签是有点问题的,然后我找了下乌云原来的样子,是长这样的
1 | 设计缺陷/边界绕过 逻辑错误 |
这样的话,我应该直接将%.+>?替换为>,然后按照>来分割,就可以了
关于厂商回复
其实我不记得厂商回复有哪些内容了,这里能看到的是厂商回应/厂商回复/最新状态/漏洞评价这四个,印象里好像还有类似厂商追加回复的,但是又没有看到,所以提取的内容里面这个就没有做的很细,直接把带有html的数据拿来了,怕遗漏了什么,其实应该抽空想办法检查一下的。
关于评论
其实内容还是主体,评论区暂时没加上,这个可以加上,有时候评论里也有很值得看的内容。
关于推荐列表
推荐列表之类的还没有做,不知道从哪入手,挺烦的其实,原来的乌云上是对优质漏洞有打雷的,不过也只是列表上的,数据库获取来的里面的数据并没有这一项,挺麻烦的。
一个优质的漏洞报告,关注的人应该很多,收藏也应该很多,但是很可惜数据库里并没有这两项指标,那么剩下的唯一指标就是评论数量和rank值了,这个到时候会对评论明显多的和自评&厂商评价高的漏洞进行整理推荐。
关于界面
没什么好说的,界面就是用了腾讯的一个前端模板程序,然后把乌云界面抄过来了,主要就是觉得设计界面太麻烦了,随便抄一个先。